
A Data-Driven Approach to Patient and Payer Risk Scoring
Medical billing involves millions of dollars in claims and reimbursements. Identifying which patients or insurance providers are likely to delay or underpay can improve cash flow, reduce bad debt, and streamline the revenue cycle. In this post, I’ll walk you through how I built a predictive credit risk model using R, tailored to the medical billing industry. *AI was used to create dummy records.*
Project Objective
The goal was to build a machine learning model that predicts the likelihood of credit risk — defined as underpayment or payment delay — based on patient and billing data.
Why this matters:
- Prevent revenue leakage
- Flag high-risk claims early
- Focus collection efforts where they matter most”
What is Credit Risk in Medical Billing?
In the context of healthcare billing, credit risk refers to:
- A patient or payer paying less than 80% of the total billed amount
- Taking more than 60 days to pay
This model helps billing departments assess which claims are at higher risk for non-collection or delay and take proactive steps.
Dataset Overview
To simulate a real-world scenario, I generated 2,000 records of dummy medical billing data with the following variables:
- Age
- Gender
- Insurance Type (Private, Medicare, Medicaid, Uninsured)
- Total Charges
- Paid Amount
- Days to Pay
- Number of Claims Last Year
- Chronic Condition (Yes/No)
- Target Variable: Credit Risk (1 = high risk, 0 = low risk)
Exploratory Data Analysis (EDA)
To understand patterns in the data, I performed the following EDA:
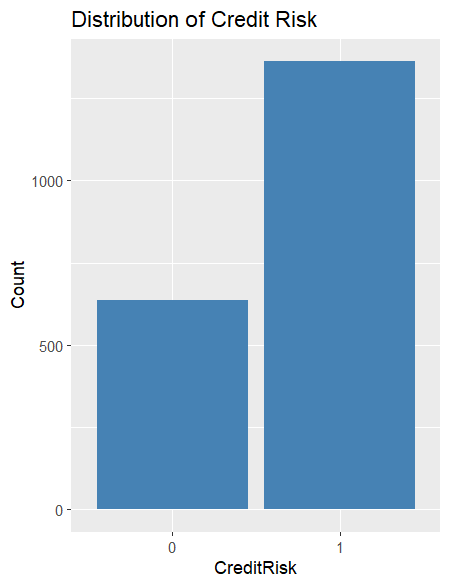
🔹 Credit Risk Distribution
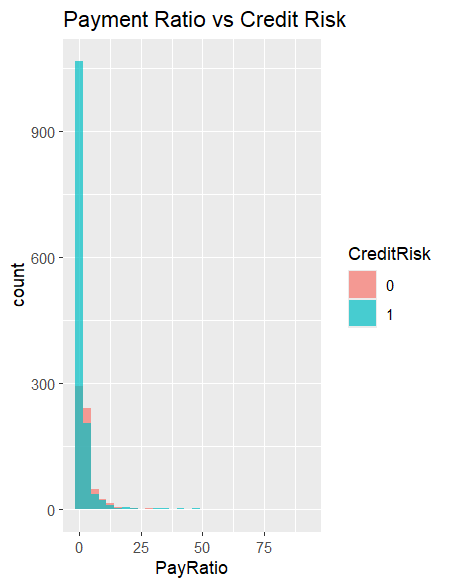
Most patients paid on time, but uninsured patients and those with chronic conditions showed significantly higher risk.
🔹 Key Trends Identified:
- Longer days to pay correlated with higher risk
- Uninsured patients showed highest non-payment rates
- Higher claim amounts increased risk, especially for chronic conditions
Here are some of the visualizations I used:
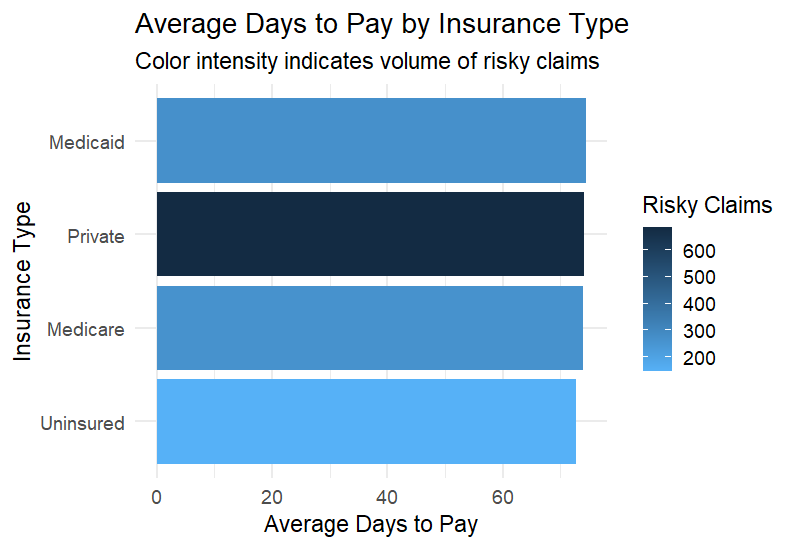
- Bar chart: Credit risk by insurance type
- Histogram: Payment ratio by credit risk
- Boxplot: Days to pay by risk level
Modeling Strategy
I used two models to compare performance:
1. Logistic Regression
- Great for explainability
- Useful for creating scorecards
- Interpretable by finance and healthcare teams
2. Random Forest
- Captures nonlinear interactions
- More accurate but less interpretable
- Ideal for automation or backend scoring systems
Logistic Regression Results
Logistic regression was trained on 80% of the data and tested on the remaining 20%.
✅ Key Predictors:
- Days to Pay
- Insurance Type
- Claim Amount
- Chronic Condition
📈 Performance:
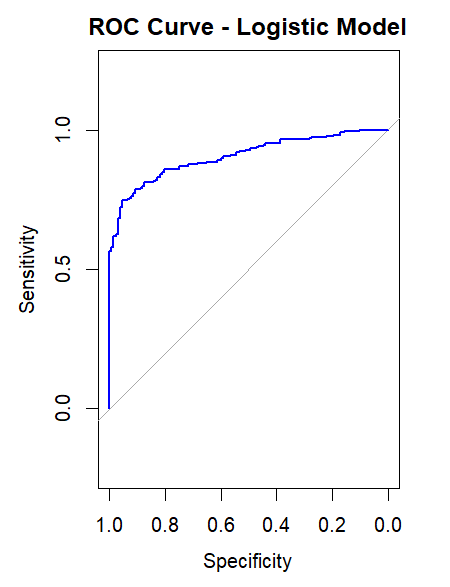
- Accuracy: ~78%
- AUC (ROC): 0.83
- Model was interpretable and gave strong early-warning indicators
Random Forest Results
Random forest was able to further improve performance and surface important interactions.
📌 Feature Importance:
- Days to Pay
- Insurance Type
- Claim Amount
📈 Performance:

- Accuracy: ~84%
- AUC (ROC): 0.89
- Best use case: Automating early risk flags in a billing system
Business Insights
After scoring the dataset, I pulled out actionable insights for stakeholders:
| Segment | Avg Days to Pay | Avg Charges | Risky Claims |
|---|---|---|---|
| Uninsured | 72 days | $5,600 | High |
| Medicaid | 64 days | $4,200 | Medium-High |
| Private | 34 days | $6,100 | Low |
| Chronic Conditions | +20% delay | +15% charge | High |
Tools Used
- R (tidyverse, caret, randomForest, pROC)
- Data simulation for realistic test case
- ggplot2 for visual storytelling
- ROC/AUC metrics to evaluate model performance
Next Steps
This model can be implemented in:
- Billing or revenue cycle software
- A Shiny app for interactive claim scoring
- Power BI dashboards via API or R backend
- Integration into claim workflows (EHRs, CRMs)
Future enhancements could include:
- Explainable AI (LIME/SHAP)
- SMOTE or cost-sensitive learning to balance the dataset
- Time series modeling for predicting future payment timelines
By tailoring machine learning models to domain-specific problems like credit risk in healthcare, we can:
- Improve revenue collection
- Support patient financial counseling
- Automate risk management within billing operations
Even a simple logistic regression model, when aligned with business logic, can drive real value.
